
Wenn wir uns daran orientieren, dann suchen wir für einen sorgfältigen Test einer Software die richtigen und wichtigen Tests (Fragen), die uns helfen, die Software zu bewerten.
Durch eine große Menge möglicher Eingabedaten ist es selbst für einfache Programme in der Regel kaum möglich, die Verarbeitung aller Datenkombinationen zu testen. Aus der Menge der möglichen Daten und Konstellationen diejenigen auszuwählen, die uns helfen, in kurzer Zeit die wichtigsten Funktionen intensiv prüfen zu können, stellt uns als Softwaretester:in vor eine Herausforderung.
Zur Ermittlung von Testfällen stehen und dafür verschiedene Software Testing Methoden zur Verfügung, die sich grundsätzlich in zwei Lager teilen: Black-Box-Test und White-Box-Tests.
Wir schauen uns heute die Methode „Äquivalenzklassenbildung“ an und führen sie anhand eines Beispiels aus. Die Äquivalenzklassenbildung gehört zu den Methoden im Black-Box-Testing.
Black Box Testing
Beim Black Box Testing ignorieren wir die innere Struktur der Software und fokussieren uns auf das von außen beobachtbare und messbare Verhalten. Dabei müssen wir als Softwaretester:in nichts über den Quellcode der Anwendung wissen.Wenn wir uns zur Ermittlung der Testfälle an den Anforderungen und Spezifikationen einer Software orientieren, so nennen wir die dafür eingesetzten Verfahren auch spezifikationsbasierte Testverfahren.
Testen mit der Äquivalenzklassenbildung
In der Äquivalenzklassenbildung schauen wir uns die Eingabe- und Ausgabeparameter einer Funktion genau an. Wir suchen hierbei Daten, für die gilt, dass sich ein bestimmter Bereich dieser Daten identisch auf das Ergebnis auswirken soll. Diese Bereiche fassen wir dann zu Äquivalenzklassen zusammen, da sie sich äquivalent auf das Ergebnis auswirken. Sie sind also untereinander austauschbar. (Hierbei ist wichtig, dass sich diese Daten nur im Hinblick auf die aktuelle Verarbeitung identisch verhalten – nicht zwingend in anderen Zusammenhängen).
Beispiel: Funktion für Alterskontrolle in einem Kassensystem
In ein Kassensystem soll eine Funktion integriert werden, welche die gesetzlich vorgeschriebene Alterskontrolle für verschiedene Produkte durch die Kassierer:innen unterstützen soll. Hierfür wird abhängig von der Produktart eine Alterskontrolle eingefordert und der Verkaufsprozess nur erlaubt, wenn der Verkauf für die Altersklasse erlaubt ist. Das erste Modul, welches integriert wird, ist die Kontrolle alkoholhaltiger Produkte.
Die Geschäftsregeln lauten:
Der Verkauf alkoholhaltiger Produkte ist in Deutschland für Personen unter 16 Jahren untersagt. An Personen, die zwischen 16 und 17 sind, dürfen Wein und Bier verkauft werden und an Person, die 18 Jahre oder älter sind, dürfen alle alkoholhaltigen Produkte verkauft werden.
Vorgehen in der Äquivalenzklassenbildung
- Identifizierung der Äquivalenzklassen
- Erstellen der logischen Testfälle
- Erstellung der konkreten Testfälle mit Repräsentanten der Äquivalenzklassen
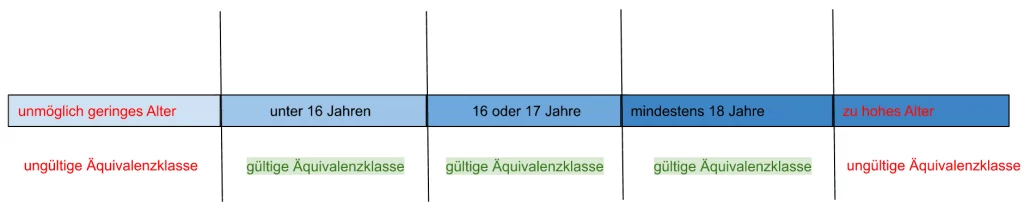
Eine Äquivalenzklasse für das Alter bilden in unserem Beispiel alle Personen zwischen 1 und 15 Jahren, da alle Elemente dieser Gruppe keinen Alkohol kaufen dürfen. Ein Repräsentant dieser Gruppe wäre unter anderem eine Person von 14 Jahren.
Eine weitere Äquivalenzklasse umfasst die Personen, die zwischen 16 und 17 Jahren alt sind. Da sich auch hier jedes Element der Gruppe gleich verhält – in unserem Fall können diese Personen Bier und Wein kaufen, aber keine hochprozentigen Alkoholika. Ein Repräsentant wäre hier eine Person von 16 Jahren.
Die letzte gültige Äquivalenzklasse wären Personen, die 18 Jahre oder älter sind. Diesen Personen dürfen alle alkoholischen Getränke verkauft werden. Hier können wir eine Person von 19 Jahren als Repräsentanten auswählen.
Falls der/die Softwaretester:in keine Äquivalenzklassen eingesetzt hätte, würde er/sie wahrscheinlich die nachstehenden Testfälle ausführen, um eine vollständige Testabdeckung zu erreichen:
1 – 15 Jahren = 15 Testfälle
16 – 17 Jahren = 2 Testfälle
18 – 110 Jahren = 93 Testfälle
Wir würden also 110 Testfälle ausführen, anstatt nur drei Testfälle. Wie eingangs beschrieben, ist es bei komplexen Programmen nicht möglich, alle Kombinationen zu testen.
Ungültige Äquivalenzklassen
In dem oberen Beispiel haben wir uns nur die gültigen Äquivalenzklassen angeschaut – also nur Äquivalenzklassen, für die eine Regel definiert ist, wie sie zu verarbeiten sind. Was machen wir aber mit den Werten, die außerhalb dieser Bereiche liegen?
In der Methodik bedienen wir uns nun dem Begriff der ungültigen Äquivalenzklassen – diejenigen Wertebereiche also, für die keine Regeln definiert sind, oder für welche die Verarbeitung nicht erlaubt ist.
In unserem Beispiel haben wir zwei ungültige Äquivalenzklassen:
- Das Alter ist <=0 (alles kleiner und gleich 0)
- Das Alter ist >110 (alles größer als 110)
Vorteile der Äquivalenzklassenbildung
Vorteile beim Software Testing mit Äquivalenzklassen-Bildung sind, dass wir mit der Erstellung von drei Testfällen in unserem Beispiel, alle Bedingungen abdecken können. Wir haben mit dem geringsten Aufwand alle möglichen gültigen Ausgabe Fälle abgedeckt.
Warum sollte ich Äquivalenzklassenbildung einsetzen?
Durch die Äquivalenzklassen-Bildung erhalten wir eine minimale Anzahl Testfälle, die alle geforderten Reaktionen auf Eingabedaten abdeckt. Wir können dadurch strukturiert die Anzahl Testfälle reduzieren und dabei die verglichen mit einer umfassenden Prüfung. Um den Testaufwand zu reduzieren und mit weniger Testfällen eine höhere Testabdeckung zu erreichen.
Welche Frage stelle ich der Anwendung mit der Äquivalenzklassenbildung?
Wir fragen die Anwendung, ob alle Fälle dem Ausgabe-Sollzustand entsprechen.
In unserem Fall müssen die möglichen Sollzustände
- Produkt darf ohne Alterskontrolle verkauft werden
- Produkt darf nach erfolgreicher Alterskontrolle verkauft werden
- Produkt darf nach nicht erfolgreicher Alterskontrolle nicht verkauft werden
den unterschiedlichen Produkten und Altersgruppen richtig zugeordnet werden. Wir minimieren also das Risiko, dass eine gültige Eingabe nicht das gewünschte Ergebnis erzielt.
Übersicht über die ermittelten Äquivalenzklassen
Wir stellen in der Analyse die Äquivalenzklassen für alle Eingabewerte und allen Ausgabewerte zusammen
Eingabe Alter:
Klasse A-I: Alter >= 0 und Alter < 16
Klasse A-II: Alter >= 16 und Alter < 18
Klasse A-III: Alter >= 18 und Alter <= 110
Klasse A-IV: Alter >110 (ungültig)
Klasse A-V: Alter < 0 (ungültig)
Eingabe Produktart:
Klasse G-1 alkoholfreie Produkte:
Klasse G-2: Bier, Wein und Alkoholmischgetränke
Klasse G-3: Spirituosen
Ausgabe Verkaufsberechtigung
Klasse V-1: Verkauf ist gestattet
Klasse V-2: Verkauf ist nicht gestattet
Mit A-IV und A-V haben wir zwei ungültige Äquivalenzklassen, da diese Werte nicht realistisch oder nicht möglich sein sollen – als Tester:innen wollen wir aber trotzdem versuchen, ob wir diese Fälle verarbeiten können und zu welchem Ergebnis wir dabei kommen.
Wir ergänzen nach Rücksprache mit dem Entwicklungsteam die Anforderung um diese Fehlerfälle.
1. Negative Zahlen dürfen nicht erfasst werden können
2. Bei zu hohem Alter wird der Benutzer gebeten, das Alter nochmals zu prüfen und im Zweifel das erlaubte Maximum von 110 einzutragen.
Deep Down the Rabbit Hole: Datentypen und Stammdaten
Wie wir oben sehen, haben wir in unserem Beispiel zwei unterschiedliche Arten von Daten. Die möglichen Werte für das Alter umfassen einen kontinuierlichen Wertebereich von Ganzzahlen (also keine Kommazahlen, diesen Datentyp nennt man auch Integer).
Bei den Produktarten haben wir keinen kontinuierlichen Bereich, sondern drei mögliche Werte – man kann diese auch als eine Aufzählung betrachten (in der Programmierung nennt man diese Datentypen in vielen Sprachen enum als Abkürzung für Enumeration, was auf Deutsch wieder Aufzählung bedeutet).
Die Kennzeichnung, zu welcher Produktkategorie die Produkte gehören, wird gewöhnlich im Kassensystem hinterlegt und automatisch abgefragt, sie muss also auch nicht eingegeben werden.
Diese Art Daten nennt man auch Stammdaten, dies sind Daten, die fix im System hinterlegt sind und somit unveränderlich, aber trotzdem nötig, um die Verarbeitung auszuführen. Die Vorbereitung der Stammdaten nimmt im Testprozess oft mehr Zeit in Anspruch als die Identifikation der nötigen Datenkonstellationen.
Testfälle ableiten
Mithilfe der identifizierten Äquivalenzklassen können wir nun Testfälle zusammenstellen. Hierfür nehmen wir jeweils eine gültige Äquivalenzklasse als Eingabewert und beschreiben, wie diese verarbeitet und welche Ausgabeäquivalenzklasse dadurch ausgelöst werden soll.
Testfall 1:
Ein Kunde im Alter [Klasse A-1] legt ein Getränk [Klasse G1] in den Warenkorb.
An der Kasse wird das Alter des Kunden geprüft.Das Kassensystem meldet Verkaufsberechtigung (V-1)
Die Erstellung der Testfälle in diesen Fällen kann aufwändig und komplex werden, aber mit der richtigen Methode und dem richtigen Vorgehen behalten wir den Überblick.
Für eine effiziente Kombinatorik bauen wir uns eine Tabelle auf, um damit die Testfälle zu definieren. Wir schreiben die Eingabe- und Ausgabedaten mit den identifizierten Äquivalenzklassen in die erste Spalte und in die Spalten rechts daneben markieren wir, welche Äquivalenzklassen wir zu einem Testfall hinzufügen wollen.

Somit kommen wir auf insgesamt 15 Testfälle durch die Kombination der Eingabewerte. Da wir bei den Testfällen nur die Äquivalenzklassen nennen und nicht die konkreten Werte, nennen wir diese Testfälle auch logische Testfälle im Gegensatz zu konkreten Testfällen, in welchen wir Repräsentanten der Klassen einsetzen.
Schauen wir uns das noch mal an einem Testfall an.
Testfall 1 – logisch:
Eine Person in der Altersklasse [Alter >= 0 und Alter < 16] möchte ein Produkt in der Klasse Alkoholgehalt [alkoholfrei] kaufen. Das Kassensystem fordert keine Alterskontrolle, der Kauf wird erlaubt.
Wir haben in diesem Testfall also keine konkreten Werte, die wir direkt anwenden könnten, sondern er referenziert ganze Klassen von Werten. Wenn wir den Testfall am System ausführen, müssen wir diese Klassen durch konkrete Werte ersetzen. Wie das aussehen wird, zeigen wir euch jetzt.
Testfall 1.1 – konkret:
Eine Person von 9 Jahren möchte eine Dose Limonade kaufen. Das Kassensystem fordert keine Alterskontrolle und erlaubt den Verkauf.
Ihr seht, dass wir den konkreten Testfall direkt ausführen können und wie wir ihn aus den Anforderungen, durch die Anwendung der Äquivalenzklassenanalyse, abgeleitet haben.
Als Tester:in möchten wir sicherstellen, dass wir alle nötigen Fälle in unseren Tests abdecken. Anhand der obigen Tabelle können wir dies erreichen, indem wir so lange Testfälle hinzufügen, bis wir alle Äquivalenzklassen in mindestens einem Test referenziert haben. Wir nennen dies auch Testabdeckung – wir wollen in den Tests eine optimale und vollständige Testabdeckung erreichen.
Wenn wir für die Testausführung nur eine limitierte Zeit zur Verfügung haben, können wir diese Testanalyse auch zur Priorisierung nutzen. Dabei führen wir für jede Äquivalenzklasse einen Testfall aus, um in die Breite zu gehen und können anschließend noch weitere Tests innerhalb der einzelnen Klassen ausführen, um weitere Risiken abzudecken.
Testfalloptimierung
Wenn wir uns die Testfälle 1–5 genauer anschauen, dann stellen wir fest, dass hierbei überhaupt keiner Abfrage des Alters nötig ist und das System die Altersprüfung anhand der Produktart nicht durchführen soll.
In solchen Fällen können wir die Anzahl Testfälle noch reduzieren, denn das Alter spielt hier überhaupt keine Rolle – vier der fünf Testfälle können wir also ohne Risiko entfernen und haben unseren Testumfang somit um ca. 30 % reduziert, ohne dabei ein Risiko einzugehen.
Die optimierte Tabelle sieht nun folgendermaßen aus:
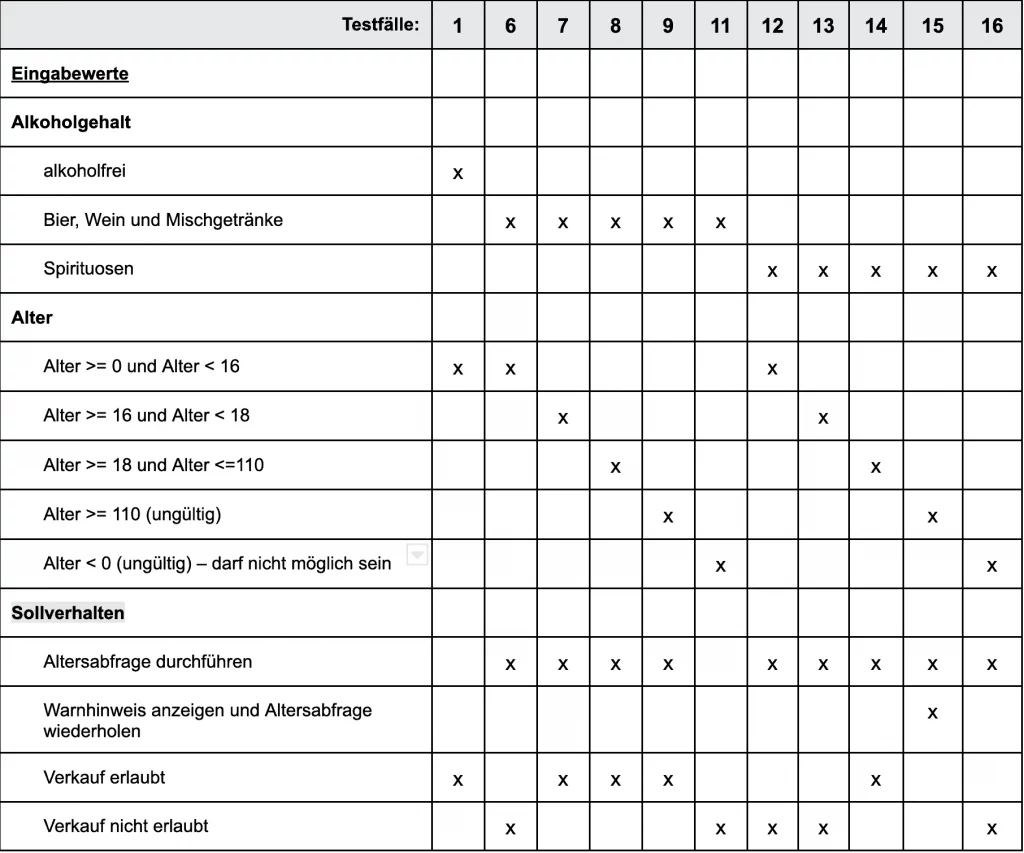
Wenn wir uns nun noch mal die Zeilen mit dem Sollverhalten anschauen in der Tabelle, dann erkennen wir auch, dass wir jedes gewünschte Sollverhalten mindestens einmal geprüft haben. Unsere Analyse ist somit abgeschlossen und wir können direkt mit dem Testen beginnen.





